语法分析是编译过程的一个逻辑阶段,传统应用中它的主要任务是在词法分析的基础上将单词符号序列组合成各类语法短语,如“程序”、“语句”、“表达式”等。语句分析程序判断源程序在结构上是否正确,源程序的结构由上下文无关文法描述。
随着软件工程领域的不断发展,对现有软件系统进行维护、重构的需求大量增加,逆向工程作为一种软件工程方法在市场需求下孕育而生,因此,对程序源代码进行逆向分析从中获取关键信息成为逆向工程的基础,语法分析有了非传统意义的运用,成为软件逆向工程中必不可少的一部分。文中语法分析模块主要包括:命令行语句的定义、分类、编码、识别、信息标注及存储结构。
1 语法分析在逆向分析中的应用
语法分析的解析对象是词法分析的结果——经过信息标注的粗粒度单词符号序列,其主要任务是基于词法分析的输出结果识别符合自定义规则的合法语法单位——命令行语句,并将这些命令行语句的信息利用编码等方式进行标注,获得含有信息标注的命令行语句序列。
1.1命令行语句的分类编码
依据Microsoft Visual Studio.NET 2003文档,深入研究c#的语法规范及特点,遵循C#语法定义的命令语句的原则——可单个执行的命令,针对源代码逆向分析获取信息的需求,自定义了一套命令行语句规则,其分类编码如图l所示。
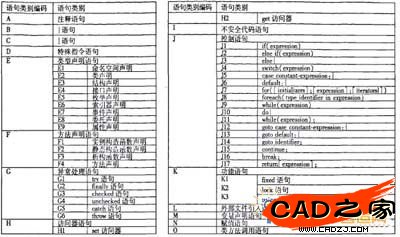
图1命令行语句的分类编码
1.2命令行语句的识别
逆向分析的源代码,来自不同的程序员,而每个程序员都拥有各自独有的编码风格。为了简化命令行语句的识别及信息提取的过程,在分析识别前首先需要对源代码进行整形处理,将不同风格的源代码统一为便于分析识别的格式,避免在语句识别或信息提取过程中多样化源代码格式带来的困扰。源代码整形处理主要包括两部分:
(1)命令行语句划分
命令行语句划分的主要任务是将不同编码风格的源代码从命令行的角度统一化,设计一种统一的程序代码行规则。在逆向分析过程中,源代码是可运行的,默认为语法无误,那么,对不要求检查语法错误的逆向分析来说,本文对命令行语句的划分采用界限符的划分方式。当然没有绝对的简单,运用此方法必须要排除一些很特殊的情况,但是这些情况都是可以通过一些的前期工作来解决。
(2)命令行语句行内格式整理
命令行语句行内格式整理的主要任务是定义命令行内单词符号间的间距格式规范,并按照这样的规范去掉命令行内不必要的空格字符、制表字符等,以达到统一命令行内的编码格式。
据统计,需要进行行内格式整理的命令行语句中涉及到的单词符号可分6类,分别为:关键字、标识符、运算符、常数、字符串、字符。需要逐个统计该6类单词符号的相邻情况,定义它们相邻的间距格式,具体如下表l单词符号间间距格式。矩阵中灰色表示两者无相邻情况,“O”表示两类单词符号间间距一个空格,“X”表示两类单词符号之间无空格间距。
表1单词符号间间距格式
对于命令行语句的识别,分为三类:第一类,注释语句、{语句}、语句、特殊指令语句,这一类语句类型的识别通过单词符号内部表示的类别信息完成;第二类,类型声明语句、异常处理语句、访问器语句、不安全代码语句、控制语句、功能语句、外部文件引入语句,这一类命令语句的类型识别通过语句中固定的C#关键字判定识别;第三类,方法声明语句、字段声明语句、变量声明语句、赋值语句、类方法调用语句,它们是一类特殊的命令语句,没有固定的C#关键字作为识别标识,这一类语句类型通过它们自独有的语句特征来识别。
1.3命令行语句的信息标注及信息结构
语法分析模块的主要功能是按照自定义的命令行语句规则进行命令行语句的划分识别,最终以包含信息标注的命令行语句序列的形式输出,并以一种固定的结构形式存储,方便信息检索。本文涉及的命令行语句信息及其信息存储结构如表2所示。
表2命令行语句信息结构

从表2可以知道,命令行语句信息结构包含5部分内容:命令行语句序号,记录命令行语句在命令行语句序列文件中的位置;命令行语句编码,表标注命令行语句的编码信息;起始单词序号,标注命令行语句的首单词符号在细粒度单词符号序列中的位置;终止单词序号,标注命令行语句的尾单词符号在细粒度单词符号序列中的位置;语句块结束语句序号,针对命令行后面有语句块的语句,标注该命令行语句的语句块结束位置。其中对命令行语句的内容采用记录命令行语句首尾单词符号在细粒度单词符号序列中的位置的方式,既方便回溯到命令行在源代码流文件中的位置,又能减少文本的储存量。并且记录了命令行语句的语句块结束位置,方便定位信息搜索范围。
2 结束语
语法分析方法作为编译系统中不可缺少的过程,对程序分析有着至关重要的作用。在深入分析、研究其工作原理的基础上,将其运用于软件逆向分析的源代码的解析过程,并详细介绍了语法分析方法在该过程中的具体应用以及该过程中涉及到的各类技术方法。随着软件工程的不断发展,语法分析方法将随着高级语言的发展应用到更多的领域。



